入力データの特徴量エンジニアリング
/ 5 min read
Table of Contents
入力データ(Feature Engineering)について
学習モデルの入力データは、ドル円の直近90分間ローリングで、1秒間隔の生データ(Raw Data)から作成している。
※ 100ms間隔の生データから作成していた時期もあった。
単純に価格そのものを入力するのではなく、価格変化、傾き、ボラティリティ、レンジ、高値・安値との位置関係など、複数の特徴量へ変換する。
例えば、
- 一定時間の価格差分
- 短期・中期トレンドの傾き
- 高値・安値レンジとの位置関係
- 反発・ブレイク傾向
- 過去の TP / SL 到達率
などを入力として追加している。
ただし、どの特徴量が本当に有効なのかは、判断できない。
重要なのは、
その特徴量を追加した結果、予測性能や収益性が改善するか
である。
新しい特徴量を追加し、
- バックテスト
- 検証データでの性能
- 実運用シミュレーション
- 損益や期待値の変化
を確認する。
改善すれば採用、悪化すれば除外する。
つまり、Feature Engineering は仮説検証の繰り返しであり、最終的には Try & Error によって有効性が判明する。
また、特徴量の有効性を分析するために、
- SHAP(SHapley Additive exPlanations)
- Simple Weight Importance(ニューラルネットワーク重みの単純積による重要度推定)
も参考指標として利用している。
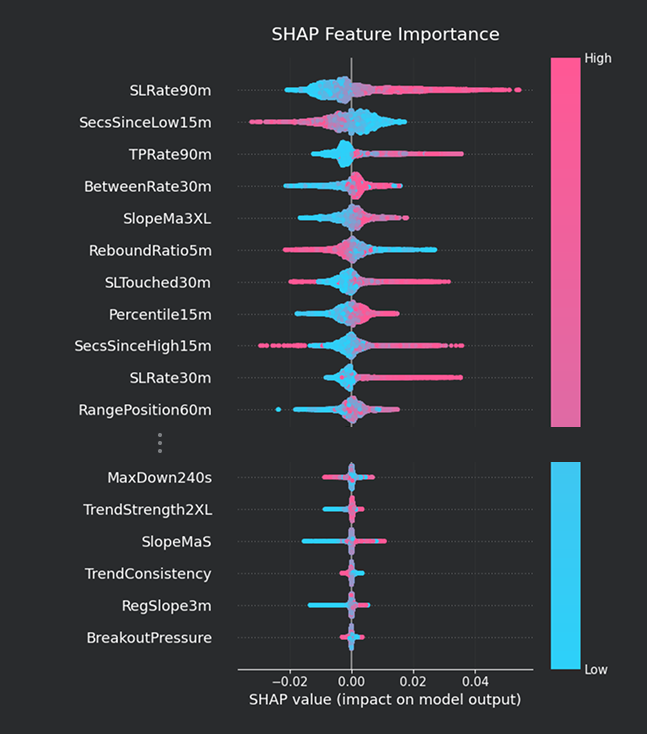
SHAP
SHAP は、
どの特徴量が予測へどの程度寄与したか
を、実際の予測結果ベースで可視化する方法である。
例えば、
「この予測では
LiquidityVacuumが強く効いた」 「この特徴量は予測をプラス方向へ押し上げた」
といった分析が可能になる。
モデルが実際に何を見て予測しているかを把握するための参考になる。
Simple Weight Importance
Simple Weight Importance は、ニューラルネットワーク内部の重みを使った、簡易的な特徴量重要度である。
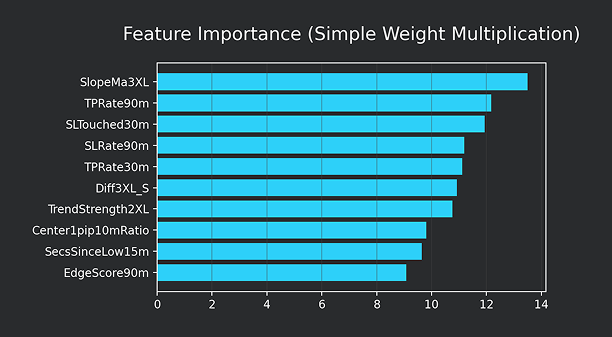
最終層(出力側)から順番に重みを掛け合わせる
ことで、各特徴量が出力までどれだけ強く接続されているかを近似的に計算している。
イメージとしては、
feature ↓hidden layer ↓hidden layer ↓outputの経路に対して、
出力層 → 中間層 → 入力層
へと重みの絶対値を掛け合わせ、その総和を特徴量ごとのスコアとしている。
つまり、
「モデル内部でどの特徴量から出力まで太い経路が存在しているか」
を可視化する考え方である。
ただし、これはニューラルネットワークの非線形性(活性化関数など)を完全には考慮していないため、厳密な重要度ではなく、あくまで簡易的な参考指標として扱っている。
最終的な判断基準は、あくまで
予測性能や収益性が改善するか
である。
一見有効そうに見える特徴量でも、実際には予測へ寄与しないことは多い。一方で、シンプルな特徴量が予想以上に効く場合もある。
そのため、
「何が正解か」はモデルに学習させ、結果で判断する
という考え方を重視している。
初期段階では約300個の特徴量候補から開始し、検証を重ねながら削除・追加を行った結果、現在は 73個の特徴量 に絞り込まれている。
ただし、これは完成形ではない。今後も、追加・削除の試行を続けていく。